

Buffalo Data Science Talk
I recently gave a talk at a Buffalo Data Science Meetup on Text Analytics in Python. It’s adapted from my post on Feature Extraction from Text with some added material and an example.
Intro to Text Analytics in Python
- Terminology
- Bag of Words Model
- TF-IDF Model
- Preprocessing and Hyperparameters
- Example
- N-gram model
Terminology
-
Document - a single string of text information
-
Corpus - a collection of documents
-
Token - a word, phrase or symbol derived from a document
-
Tokenizer - function to split a document into a list of tokens
# Example corpus
messages = ["Hey hey hey lets go get lunch today :)",
"Did you go home?",
"Hey!!! I need a favor"]
# Example document
document = messages[0]
document
'Hey hey hey lets go get lunch today :)'
# Creating tokens
document.split(' ')
['Hey', 'hey', 'hey', 'lets', 'go', 'get', 'lunch', 'today', ':)']
Bag of Words Model
- need a numerical representation for our corpus
- will use CountVectorizer() from sci-kit learn library
- creates matrix of token counts
# import and instantiate CountVectorizer()
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
- next we will use fit() and transform() methods
- similar to fit() and predict() used in ML classifiers
vect.fit(messages)
CountVectorizer(analyzer=u'word', binary=False, decode_error=u'strict',
dtype=<type 'numpy.int64'>, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern=u'(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
# before transforming look at feature names (columns names)
print vect.get_feature_names()
print 'Number of tokens: {}'.format(len(vect.get_feature_names()))
[u'did', u'favor', u'get', u'go', u'hey', u'home', u'lets', u'lunch', u'need', u'today', u'you']
Number of tokens: 11
Things to note:
- all lowercase
- words less than two letters are excluded
- punctuation removed
- no duplicates
Next, we’ll use the transform() method to create a document term matrix(DTM). This is the matrix of token counts we want to create.
dtm = vect.transform(messages)
repr(dtm)
"<3x11 sparse matrix of type '<type 'numpy.int64'>'\n\twith 13 stored elements in Compressed Sparse Row format>"
print dtm
(0, 2) 1
(0, 3) 1
(0, 4) 3
(0, 6) 1
(0, 7) 1
(0, 9) 1
(1, 0) 1
(1, 3) 1
(1, 5) 1
(1, 10) 1
(2, 1) 1
(2, 4) 1
(2, 8) 1
- Because each document has a column for every word that occurs in the corpus, DTM is predominatly filled with 0’s
- Sparse format can store the DTM in a smaller amount of memory and can speed up operations
- a DTM of a large corpus can quickly balloon in size
import pandas as pd
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
| did | favor | get | go | hey | home | lets | lunch | need | today | you | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 3 | 0 | 1 | 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
# get total counts for corpus
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names()).sum()
did 1
favor 1
get 1
go 2
hey 4
home 1
lets 1
lunch 1
need 1
today 1
you 1
dtype: int64
What happens if we get a new message?
new_message = ['Hey lets go get a drink tonight']
new_dtm = vect.transform(new_message)
pd.DataFrame(new_dtm.toarray(), columns=vect.get_feature_names())
| did | favor | get | go | hey | home | lets | lunch | need | today | you | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
- only tokens from original fit appear as features(columns)
- need to refit with new message included
messages.append(new_message[0])
messages
['Hey hey hey lets go get lunch today :)',
'Did you go home?',
'Hey!!! I need a favor',
'Hey lets go get a drink tonight']
dtm = vect.fit_transform(messages)
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
| did | drink | favor | get | go | hey | home | lets | lunch | need | today | tonight | you | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 1 | 3 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
TF-IDF Model
- term frequency inverse document frequency
- generally more popular than bag of words model
- numerical statistic to show how important an token is to a document
- TF-IDF = term frequency * (1 / document frequency)
- TF - how frequent a term(token) occurs in a document
- IDF - inverse of how frequent a term occurs across documents
from sklearn.feature_extraction.text import TfidfVectorizer
def createDTM(messages):
vect = TfidfVectorizer()
dtm = vect.fit_transform(messages) # create DTM
# create pandas dataframe of DTM
return pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
messages = ["Hey lets get lunch :)",
"Hey!!! I need a favor"]
createDTM(messages)
| favor | get | hey | lets | lunch | need | |
|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.534046 | 0.379978 | 0.534046 | 0.534046 | 0.000000 |
| 1 | 0.631667 | 0.000000 | 0.449436 | 0.000000 | 0.000000 | 0.631667 |
'hey'has lowest value, only word that occurs in both documents'favor'and'need'have highest, occur in 1 document with fewest tokens
# add repeats of 'hey' to first message
messages = ["Hey hey hey lets get lunch :)",
"Hey!!! I need a favor"]
createDTM(messages)
| favor | get | hey | lets | lunch | need | |
|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.363788 | 0.776515 | 0.363788 | 0.363788 | 0.000000 |
| 1 | 0.631667 | 0.000000 | 0.449436 | 0.000000 | 0.000000 | 0.631667 |
- TF for
'hey'in first increases, but IDF for'hey'remains the same
# remove 'hey' from second message
messages = ["Hey hey hey lets get lunch :)",
"I need a favor"]
createDTM(messages)
| favor | get | hey | lets | lunch | need | |
|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.288675 | 0.866025 | 0.288675 | 0.288675 | 0.000000 |
| 1 | 0.707107 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.707107 |
'hey'for first message is now the highest value'favor'and'need'also increase as there are now fewer tokens in the second message
Preprocessing and Hyperparameters
- max_features = n : only considers the top n words when ordered by term frequency
- min_df = n : ignores words with a document frequency below n
- max_df = n : ignores words with a document frequency above n
- stop_words = [’’] : ignores common words like
'the','that','which'etc.
vect = CountVectorizer(stop_words='english')
print vect.get_stop_words()
frozenset(['all', 'six', 'less', 'being', 'indeed', 'over', 'move', 'anyway', 'four', 'not', 'own', 'through', 'yourselves', 'fify', 'where', 'mill', 'only', 'find', 'before', 'one', 'whose', 'system', 'how', 'somewhere', 'with', 'thick', 'show', 'had', 'enough', 'should', 'to', 'must', 'whom', 'seeming', 'under', 'ours', 'has', 'might', 'thereafter', 'latterly', 'do', 'them', 'his', 'around', 'than', 'get', 'very', 'de', 'none', 'cannot', 'every', 'whether', 'they', 'front', 'during', 'thus', 'now', 'him', 'nor', 'name', 'several', 'hereafter', 'always', 'who', 'cry', 'whither', 'this', 'someone', 'either', 'each', 'become', 'thereupon', 'sometime', 'side', 'two', 'therein', 'twelve', 'because', 'often', 'ten', 'our', 'eg', 'some', 'back', 'up', 'go', 'namely', 'towards', 'are', 'further', 'beyond', 'ourselves', 'yet', 'out', 'even', 'will', 'what', 'still', 'for', 'bottom', 'mine', 'since', 'please', 'forty', 'per', 'its', 'everything', 'behind', 'un', 'above', 'between', 'it', 'neither', 'seemed', 'ever', 'across', 'she', 'somehow', 'be', 'we', 'full', 'never', 'sixty', 'however', 'here', 'otherwise', 'were', 'whereupon', 'nowhere', 'although', 'found', 'alone', 're', 'along', 'fifteen', 'by', 'both', 'about', 'last', 'would', 'anything', 'via', 'many', 'could', 'thence', 'put', 'against', 'keep', 'etc', 'amount', 'became', 'ltd', 'hence', 'onto', 'or', 'con', 'among', 'already', 'co', 'afterwards', 'formerly', 'within', 'seems', 'into', 'others', 'while', 'whatever', 'except', 'down', 'hers', 'everyone', 'done', 'least', 'another', 'whoever', 'moreover', 'couldnt', 'throughout', 'anyhow', 'yourself', 'three', 'from', 'her', 'few', 'together', 'top', 'there', 'due', 'been', 'next', 'anyone', 'eleven', 'much', 'call', 'therefore', 'interest', 'then', 'thru', 'themselves', 'hundred', 'was', 'sincere', 'empty', 'more', 'himself', 'elsewhere', 'mostly', 'on', 'fire', 'am', 'becoming', 'hereby', 'amongst', 'else', 'part', 'everywhere', 'too', 'herself', 'former', 'those', 'he', 'me', 'myself', 'made', 'twenty', 'these', 'bill', 'cant', 'us', 'until', 'besides', 'nevertheless', 'below', 'anywhere', 'nine', 'can', 'of', 'toward', 'my', 'something', 'and', 'whereafter', 'whenever', 'give', 'almost', 'wherever', 'is', 'describe', 'beforehand', 'herein', 'an', 'as', 'itself', 'at', 'have', 'in', 'seem', 'whence', 'ie', 'any', 'fill', 'again', 'hasnt', 'inc', 'thereby', 'thin', 'no', 'perhaps', 'latter', 'meanwhile', 'when', 'detail', 'same', 'wherein', 'beside', 'also', 'that', 'other', 'take', 'which', 'becomes', 'you', 'if', 'nobody', 'see', 'though', 'may', 'after', 'upon', 'most', 'hereupon', 'eight', 'but', 'serious', 'nothing', 'such', 'your', 'why', 'a', 'off', 'whereby', 'third', 'i', 'whole', 'noone', 'sometimes', 'well', 'amoungst', 'yours', 'their', 'rather', 'without', 'so', 'five', 'the', 'first', 'whereas', 'once'])
# defining our own stopwords
my_words = ['buffalo','data','science']
vect = CountVectorizer(stop_words=my_words)
print vect.get_stop_words()
frozenset(['data', 'buffalo', 'science'])
Word Stemming
- reduces a word down to its base/root form
- crude heuristic that works by chopping off end of word
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
tokens = ['manufactured','manufacturing','manufacture']
stems = [stemmer.stem(i) for i in tokens]
print stems
[u'manufactur', u'manufactur', u'manufactur']
Word Lemmatization
- similar to stemming
- seeks to find base dictionary form
- more complex, may need to specify part of speech for accurate results
from nltk import WordNetLemmatizer
lemmer = WordNetLemmatizer()
tokens = ['hands','women']
lemmas = [lemmer.lemmatize(i) for i in tokens]
print lemmas
[u'hand', u'woman']
lemmer.lemmatize('manufacturing')
'manufacturing'
# specify it as a verb, default is noun
lemmer.lemmatize('manufacturing','v')
u'manufacture'
Example
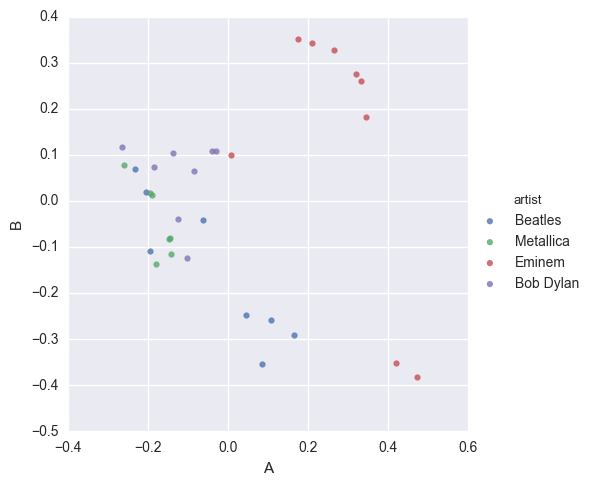
- dataset of song lyrics from 4 different artists (Beatles, Metallica, Eminem, Bob Dylan)
- we will use a vectorizer and then try to plot
- would expect similar songs to be close together
df = pd.read_csv('lyrics.txt', sep='\t')
df
| artist | song | lyrics | |
|---|---|---|---|
| 0 | Beatles | Help! | (When) When I was younger (When I was young) s... |
| 1 | Beatles | Ticket to Ride | I think I'm gonna be sad, I think it's today, ... |
| 2 | Beatles | A Hard Days Night | It's been a hard day's night, and I been worki... |
| 3 | Beatles | Cant Buy Me Love | Can't buy me love, love Can't buy me love I'll... |
| 4 | Beatles | Eleanor Rigby | Ah look at all the lonely people Ah look at al... |
| 5 | Beatles | I Want to Hold Your Hand | Oh yeah, I'll tell you something I think you'l... |
| 6 | Beatles | She Loves You | She loves you, yeah, yeah, yeah She loves you,... |
| 7 | Beatles | Yesterday | Yesterday all my troubles seemed so far away. ... |
| 8 | Metallica | Nothing Else Matters | So close no matter how far Couldn't be much mo... |
| 9 | Metallica | Enter Sandman | Say your prayers, little one Don't forget, my ... |
| 10 | Metallica | Master of Puppets | End of passion play, crumbling away I’m your s... |
| 11 | Metallica | The Unforgiven | New blood joins this earth, And quickly he's s... |
| 12 | Metallica | Fade to Black | Life, it seems, will fade away Drifting furthe... |
| 13 | Metallica | One | I can’t remember anything Can’t tell if this i... |
| 14 | Metallica | For Whom the Bell Tolls | Make his fight on the hill in the early day Co... |
| 15 | Eminem | The Real Slim Shady | May I have your attention please? May I have y... |
| 16 | Eminem | Till I Collapse | 'Cause sometimes you just feel tired, Feel wea... |
| 17 | Eminem | Lose Yourself | Look, if you had, one shot, or one opportunity... |
| 18 | Eminem | Stan | My tea's gone cold I'm wondering why I got out... |
| 19 | Eminem | My Name Is | Hi! My name is... (what?) My name is... (who?)... |
| 20 | Eminem | Like Toy Soldiers | Step by step, heart to heart, left right left ... |
| 21 | Eminem | When I'm Gone | Yeah... It's my life... My own words I guess..... |
| 22 | Eminem | Mockingbird | Yeah I know sometimes things may not always ma... |
| 23 | Eminem | Without Me | Obie Trice/Real Name No Gimmicks [2x] two trai... |
| 24 | Bob Dylan | Blowin in the Wind | How many roads must a man walk down Before you... |
| 25 | Bob Dylan | Mr Tambourin Man | Hey ! Mr Tambourine Man, play a song for me I'... |
| 26 | Bob Dylan | Its All Over Now Baby Blue | You must leave now, take what you need, you th... |
| 27 | Bob Dylan | The Times They are A-changin | Come gather 'round people Wherever you roam An... |
| 28 | Bob Dylan | Hurricane | Pistols shots ring out in the barroom night En... |
| 29 | Bob Dylan | It aint me babe | Go 'way from my window Leave at your own chose... |
| 30 | Bob Dylan | Maggies Farm | I ain't gonna work on Maggie's farm no more No... |
| 31 | Bob Dylan | A Hard Rains A-gonna Fall | Oh, where have you been, my blue-eyed son? And... |
vect = TfidfVectorizer(stop_words='english',max_df=0.7)
dtm = vect.fit_transform(df['lyrics'])
repr(dtm)
"<32x1984 sparse matrix of type '<type 'numpy.float64'>'\n\twith 3471 stored elements in Compressed Sparse Row format>"
- we can’t plot 1984 dimensions in an effective way
- need to reduce dimensionality to 2 dimensions
- use Principle Component Analysis (PCA)
- describes data using smaller number of dimensions
- trys to retain variance and ‘structure’ of the data
# Principle Component Analysis (PCA) to reduce down to two dimensions
from sklearn.decomposition import PCA
X_pca = PCA(n_components=2).fit_transform(dtm.toarray())
df['A'] = X_pca[:,0]
df['B'] = X_pca[:,1]
df.head()
| artist | song | lyrics | A | B | |
|---|---|---|---|---|---|
| 0 | Beatles | Help! | (When) When I was younger (When I was young) s... | -0.204841 | 0.018931 |
| 1 | Beatles | Ticket to Ride | I think I'm gonna be sad, I think it's today, ... | 0.107004 | -0.258968 |
| 2 | Beatles | A Hard Days Night | It's been a hard day's night, and I been worki... | 0.044426 | -0.247208 |
| 3 | Beatles | Cant Buy Me Love | Can't buy me love, love Can't buy me love I'll... | 0.085107 | -0.354033 |
| 4 | Beatles | Eleanor Rigby | Ah look at all the lonely people Ah look at al... | -0.232241 | 0.069967 |
import seaborn as sns
import matplotlib.pyplot as plt
sns.lmplot(x='A', y='B', data=df,fit_reg=False, hue='artist')
plt.show()
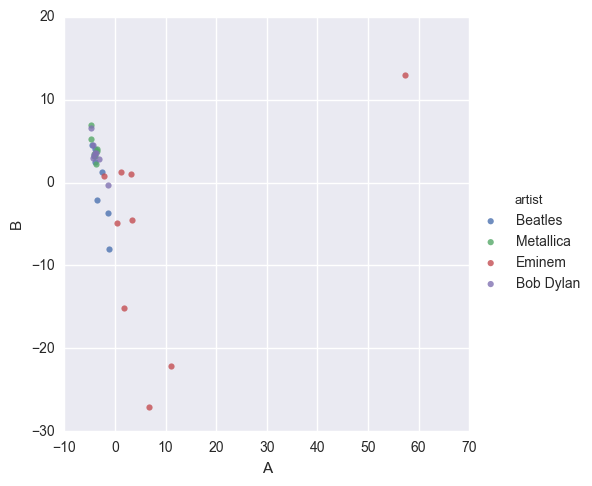
If we had used CountVectorizer instead of TfidfVectorizer:
N-gram Model
- n-gram is a sequence of n words
- bag of words model is actually a specific case of the N-gram model where n=1
- Consider the string
'Buffalo Data Science Meetup' - n=1 (unigram) :
'Buffalo','Data','Science','Meetup'(Bag of words model) - n=2 (bigram) :
'Buffalo Data','Data Science','Science Meetup' - n=3 (trigram) :
'Buffalo Data Science','Data Science Meetup’ - using n-gram model info about order of tokens
messages = ["Hey hey hey lets go get lunch today :)",
"Hey!!! I need a favor"]
# look at bigrams
vect = CountVectorizer(ngram_range=(2,2))
dtm = vect.fit_transform(messages)
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
| get lunch | go get | hey hey | hey lets | hey need | lets go | lunch today | need favor | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 1 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
# look at trigrams
vect = CountVectorizer(ngram_range=(3,3))
dtm = vect.fit_transform(messages)
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
| get lunch today | go get lunch | hey hey hey | hey hey lets | hey lets go | hey need favor | lets go get | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
# looking at unigrams, bigrams, and trigrams
vect = CountVectorizer(ngram_range=(1,3))
dtm = vect.fit_transform(messages)
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
| favor | get | get lunch | get lunch today | go | go get | go get lunch | hey | hey hey | hey hey hey | ... | hey need | hey need favor | lets | lets go | lets go get | lunch | lunch today | need | need favor | today | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 3 | 2 | 1 | ... | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
2 rows × 23 columns
# Can also use with tf-idf
vect = TfidfVectorizer(ngram_range=(2,2))
dtm = vect.fit_transform(messages)
pd.DataFrame(dtm.toarray(), columns=vect.get_feature_names())
| get lunch | go get | hey hey | hey lets | hey need | lets go | lunch today | need favor | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.333333 | 0.333333 | 0.666667 | 0.333333 | 0.000000 | 0.333333 | 0.333333 | 0.000000 |
| 1 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.707107 | 0.000000 | 0.000000 | 0.707107 |
Questions?